Area of Applicability for Deep Learning: Exploring Latent Space Geometry of Earth Observation Models
EGU2026
2026-05-06
Research question
Area of Applicability (Meyer and Pebesma 2021) defines the domain in which a model is trusted to operate within estimated performance measures
Our hypothesis is that:
Latent representations learned by deep models provide a computationally efficient and reliable basis for defining an Area of Applicability for Earth Observation models.
We are analyzing the question:
Under which conditions do distance-based confidence scores in the latent space of a deep model favourably delinate the Area of Applicability?

Average effects of analysed parameters on preservation and separation for classification.
Distances in representation space




Problem setting
In the real world, models might be used for inference on samples which are outside of their domain of application.

Example of overconfident predictions for OOD samples (Hou 2023.)
Neural network-based classifiers may silently fail when the test data distribution differs from the training data. For critical tasks such as medical diagnosis or autonomous driving, it is thus essential to detect incorrect predictions based on an indication of whether the classifier is likely to fail.
Jaeger et al. (2023)
Dataset

Methodology

Percentage of rejected samples

Average rejected percentage for classification (C) by country and distance metric. Error bars represent the range over all configurations.
Increase in error

Average increase in error for classification (C) by country and selection. Error bars represent the range over all configurations.
Selected and rejected samples

Effects

Overall results
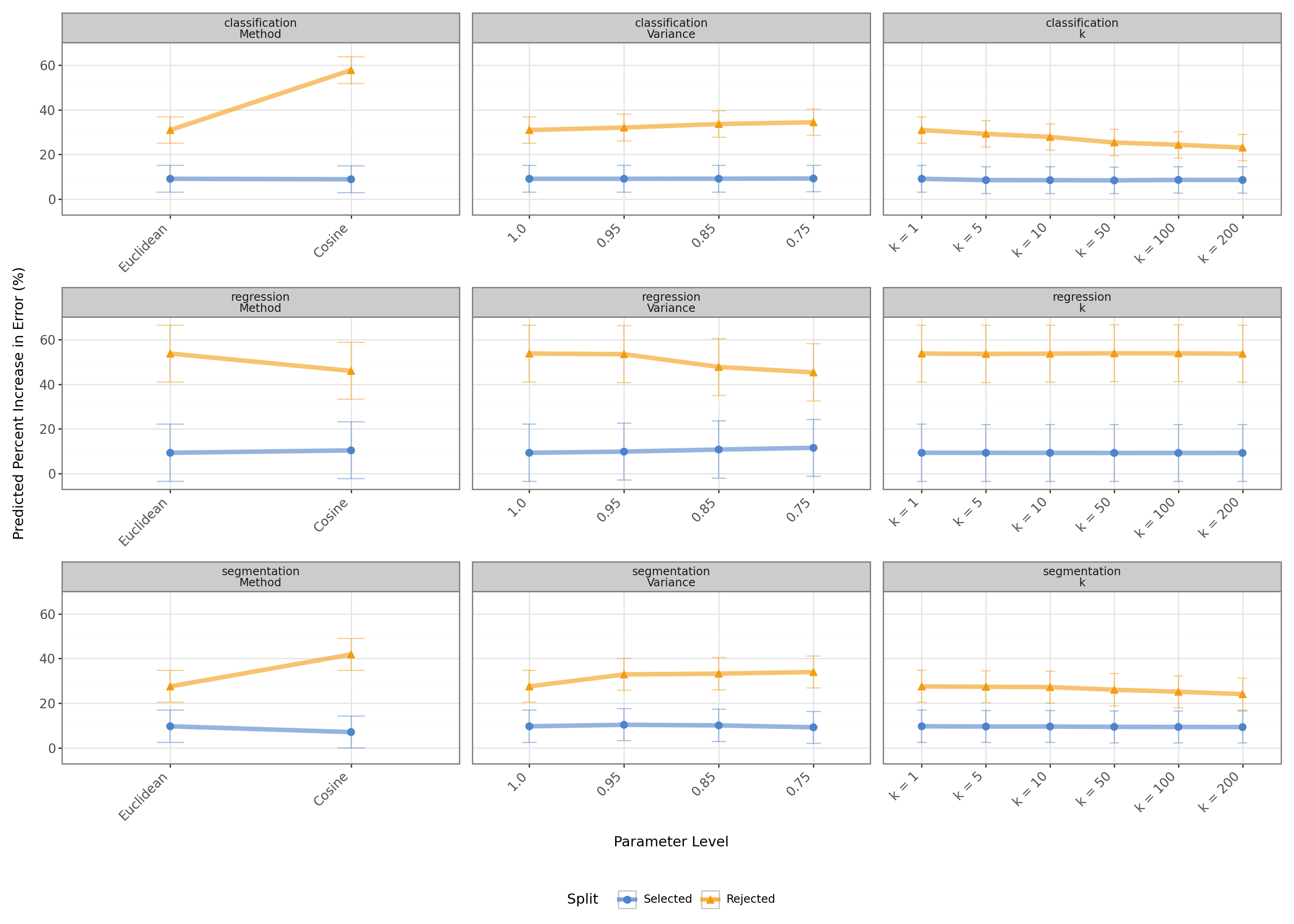
Preservation
- Selected samples ≈ +9% error; configs have no major effect
- Exception: lower PCA variance worsens R (+2.2% at 0.75)
Separation
- Rejected samples have much higher error (17–44%)
- Cosine: helps C (+27%) & S (+17%), hurts R (−8.9%)
- Lower PCA variance: helps C (+3.3%) & S (+6.9%), hurts R (−10.7%)
- Increasing K: no effect on R; harms C (-7.3%) and S (−3%)
Classification results
Average rejected percentage for classification (C) by country and distance metric. Error bars represent the range over all configurations.
Classification results
Average increase in error for classification (C) by country and selection. Error bars represent the range over all configurations.
Classification results

In-distribution error versus out-of-distribution error (each dot represents the average over a country dataset).
Regression results

Regression results

Regression results

In-distribution error versus out-of-distribution error (each dot represents the average over a country dataset).
Segmentation results

Segmentation results

Segmentation results

In-distribution error versus out-of-distribution error (each dot represents the average over a country dataset).